

The One Weird Trick That Gave Humans Language
An Extract From 'A Brief History of Intelligence' by Max Bennett


Catch-up service:
10 Classical Music Pieces To Take On Holiday
The Diderot Effect
Keir Starmer’s Reality Avoidance Field
27 Notes on Growing Old(er)
Donald Trump and the End of Power
5 Reasons There Won’t Be an AI Jobs Apocalypse
“I found this book amazing. I read it through quickly because it was so interesting, then turned around and read much of it again.”—Daniel Kahneman, author of Thinking Fast & Slow.
I’m with Kahneman. A Brief History of Intelligence, by Max Bennett, is the best science book I’ve read in years. I’ll be having Max on the podcast soon to discuss it. In the meantime (and while I’m on holiday) I’m delighted to publish an extract from his book. (This post is free to read.)
A Brief History tells the story of how human intelligence evolved, by way of five “breakthroughs”. It starts with nematodes - tiny worms - 600 million years ago, and ends with us. One of the striking things I learnt is how similar human brains are to those of fish and most other animals. It was really only the capacity to speak, using language - Bennett’s fifth and last ‘breakthrough’ - that saw us pull away from the pack.
I love the scope of this book; it’s a vast story, elegantly and economically told. Bennett is not an academic - though his book is meticulously researched - but an AI entrepreneur, and he is very good on how the science of AI has been informed by our understanding of organic intelligence, and vice versa: the struggle to develop AI is helping scientists understand more about human intelligence.
What follows is an extract from Breakthrough #5. In it, Max gives us a lucid account of a neuroscientific puzzle. What exactly is it about the human brain that enables us to speak in language? The answer is surprising. Before beginning the extract I’ll briefly summarise what we learn in the first part of this chapter:
About 150 years ago, scientists discovered two specific areas of the brain used for language, by studying the brains of patients with language deficiencies. Patients who couldn’t speak but who were intellectually intact in every other way were found to have damage to a region now known as Broca’s area. Patients who could speak fluently but made no sense, producing only gibberish, were found to have damage to a region now known as Wernicke’s Area. Broca’s area governs production of speech; Wernicke’s Area comprehension.
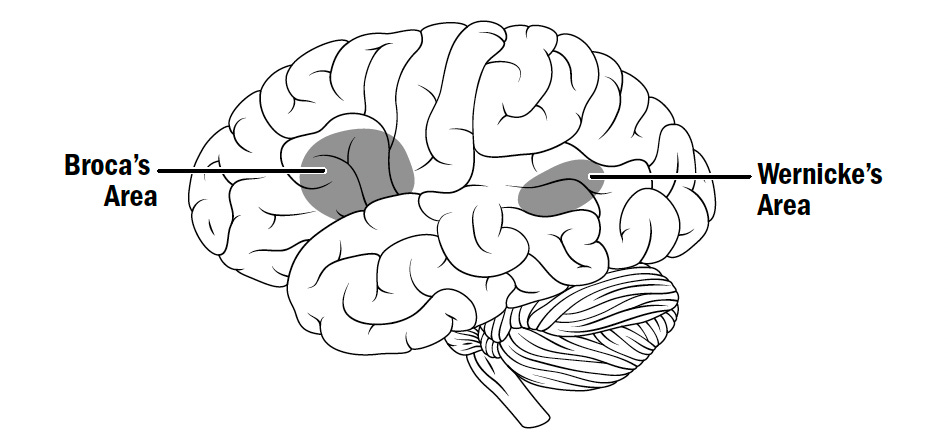
Both areas are remarkably specific: they're selective for language itself, not just speech. Damage to Broca's area impairs speaking, writing, and signing equally. These discoveries revealed that language emerges from specific brain regions, dissociated from other intellectual abilities. In other words, language isn’t simply a byproduct of having a bigger brain than a chimp; it is a specific and independent skill that evolution wove into our brains. The most dramatic example of this is a child who was severely cognitively impaired, couldn't button a shirt or win at tic-tac-toe, yet could read, write, and speak over fifteen languages extremely well. His language areas were brilliant, while the rest of his brain was impaired.
OK, over to Max…
So this would seem to close the case. We have found the language organ of the human brain: humans evolved two new areas of neocortex—Broca’s and Wernicke’s areas—which are wired together into a specific subnetwork specialised for language. This subnetwork gifted us language, and that is why humans have language and other apes don’t. Case closed.
Unfortunately, the story is not so simple.
The following fact complicates things: Your brain and a chimpanzee brain are practically identical; a human brain is, almost exactly, just a scaled-up chimpanzee brain. This includes the regions known as Broca’s area and Wernicke’s area. These areas did not evolve in early humans; they emerged much earlier, in the first primates. They are part of the areas of the neocortex that emerged with the breakthrough of mentalizing. Chimpanzees, bonobos, and even macaque monkeys all have exactly these areas with practically identical connectivity. Thus, it was not the emergence of Broca’s or Wernicke’s areas that gave humans the gift of language.
Perhaps human language was an elaboration on the existing system of ape communication? This might explain why these language areas are still present in other primates. Chimpanzees, bonobos, and gorillas all have sophisticated suites of gestures and hoots that signal different things. Wings evolved from arms, and multicellular organisms evolved from single-celled organisms, so it would make sense if human language evolved from the more primitive communication systems of our ape ancestors. But this is not how language evolved in the brain.
In other primates, these language areas of the neocortex are present but have nothing to do with communication. If you damage Broca’s and Wernicke’s areas in a monkey, it has no impact on monkey communication. If you damage them in humans, we lose the ability to use language entirely.
When we compare ape gestures to human language, we are comparing apples to oranges. Their common use for communication obscures the fact that they are entirely different neurological systems without any evolutionary relationship to each other.
Humans have, in fact, inherited the exact same communication system of apes, but it isn’t our language— it is our emotional expressions.
In the mid-1990s, a teacher in his fifties noticed that he was struggling to speak. Over the course of three days, his symptoms worsened. By the time he made it to the doctor, the right side of his face was paralysed, and the man’s speech was slowed and slurred. When he was asked to smile, only one side of his face would move, leading to a lopsided smirk.
When examining the man, the doctor noticed something perplexing. When the doctor told a joke or said something genuinely pleasant, the man could smile just fine. The left side of his face worked normally when he was laughing, but when he was asked to smile voluntarily, the man was unable to do it.
The human brain has parallel control of facial expressions; there is an older emotional- expression system that has a hard- coded mapping between emotional states and reflexive responses. This system is controlled by ancient structures like the amygdala. Then there is a separate system that provides voluntary control of facial muscles that is controlled by the neocortex.

It turned out that this teacher had a lesion in his brain stem that had disrupted the connection between his neocortex and the muscles on the left side of his face but had spared the connection between his amygdala and those same muscles. This meant that he couldn’t voluntarily control the left side of his face, but his emotional- expression system could control his face just fine. While he was unable to voluntarily lift an eyebrow, he was eminently able to laugh, frown, and cry.
This is also seen in individuals with severe forms of Broca’s and Wernicke’s aphasia. Even individuals who can’t utter a single word can readily laugh and cry. Why? Because emotional expressions emerge from a system entirely separate from language.
The apples- to- apples comparison between ape and human communication is between ape vocalisations and human emotional expressions. To simplify a bit: Other primates have a single communication system, their emotional- expression system, located in older areas like the amygdala and brainstem. It maps emotional states to communicative gestures and sounds. Indeed, as noticed by Jane Goodall, “the production of a sound in the absence of the appropriate emotional state seems to be an almost impossible task [for chimpanzees].” This emotional- expression system is ancient, going back to early mammals, perhaps even earlier.
Humans, however, have two communication systems— we have this same ancient emotional expression system and we have a newly evolved language system in the neocortex.
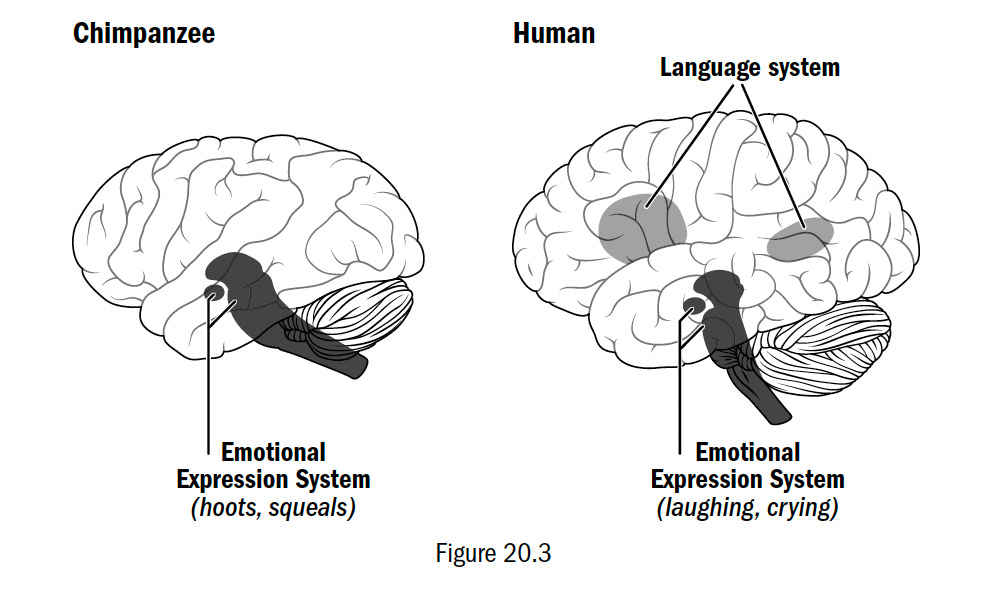
Human laughs, cries, and scowls are evolutionary remnants of an ancient and more primitive system for communication, a system from which ape hoots and gestures emerge. However, when we speak words, we are doing something without any clear analogue to any system of ape communication.
This explains why lesions to Broca’s and Wernicke’s areas in monkeys have absolutely no impact on communication. A monkey can still hoot and holler for the same reason a human with such damage can still laugh, cry, smile, frown, and scowl even while he can’t utter a single coherent word. The gestures of monkeys are automatic emotional expressions and don’t emerge from the neocortex; they are more like a human laugh than language.
The emotional-expression system and the language system have another difference: one is genetically hardwired, and the other is learned. The shared emotional-expression system of humans and other apes is, for the most part, genetically hardwired. As evidence, monkeys who are raised in isolation still end up producing all of their normal gesture-call behaviour, and chimpanzees and bonobos share almost 90 percent of the same gestures. Similarly, human cultures and children from around the world have remarkable overlap in emotional expressions, suggesting that at least some parts of our emotional expressions are genetically hard-coded and not learned. All human beings (even those born blind and deaf) cry, smile, laugh, and frown in relatively similar ways in response to similar emotional states.
However, the newer language system in humans is incredibly sensitive to learning—if a child goes long enough without being taught language, he or she will be unable to acquire it later in life. Unlike innate emotional expressions, features of language differ greatly across cultures. And indeed, a human baby born without any neocortex will still express these emotions in the usual way but will never speak.
So here is the neurobiological conundrum of language. Language did not emerge from some newly evolved structure. Language did not emerge from humans’ unique neocortical control over the larynx and face. Language did not emerge from some elaboration of the communication systems of early apes. And yet, language is entirely new. So what unlocked language?
All birds know how to fly. Does this mean that all birds have genetically hardwired knowledge of flying? Well, no. Birds are not born knowing how to fly; all baby birds must independently learn how to fly. They start by flapping wings, trying to hover, making their first glide attempt, and eventually, after enough repetitions, they figure it out. But if flying is not genetically hard-coded, then how is it that approximately 100 percent of all baby birds independently learn such a complex skill?
A skill as sophisticated as flying is too information-dense to hard-code directly into a genome. It is more efficient to encode a generic learning system (such as a cortex) and a specific hardwired learning curriculum (instinct to want to jump, instinct to flap wings, and instinct to attempt to glide). It is the pairing of a learning system and a curriculum that enables every single baby bird to learn how to fly.
In the world of artificial intelligence, the power and importance of curriculum is well known. In the 1990s, a linguist and professor of cognitive sciences at UC San Diego, Jeffrey Elman, was one of the first to use neural networks to try to predict the next word in a sentence given the previous words. The learning strategy was simple: Keep showing the neural network word after word, sentence after sentence, have it predict the next word based on the prior words, then nudge all the weights in the network toward the right answer each time. Theoretically, it should have been able to correctly predict the next word in a novel sentence it had never seen before.
It didn’t work.
Then Elman tried something different. Instead of showing the neural network sentences of all levels of complexity at the same time, he first showed it extremely simple sentences, and only after the network performed well at these did he increase the level of complexity. In other words, he designed a curriculum. And this, it turned out, worked. After being trained with this curriculum, his neural network could correctly complete complex sentences.
This idea of designing a curriculum for AI applies not just to language but to many types of learning. Remember the model-free reinforcement algorithm TD-Gammon? TD-Gammon enabled a computer to outperform humans in the game of backgammon. I left out a crucial part of how TD-Gammon was trained. It did not learn through the trial and error of endless games of backgammon against a human expert. If it had done this, it would never have learned, because it would never have won. TD-Gammon was trained by playing against itself. TD-Gammon always had an evenly matched player. This is the standard strategy for training reinforcement learning systems. DeepMind’s AlphaZero was also trained by playing itself. The curriculum used to train a model is as crucial as the model itself.
To teach a new skill, it is often easier to change the curriculum instead of changing the learning system. Indeed, this is the solution that evolution seems to have repeatedly settled on when enabling complex skills—monkey climbing, bird flying, and, yes, even human language all seem to work this way. They emerge from newly evolved hardwired curriculums.
Long before human babies engage in conversations using words, they engage in what are called proto-conversations. By four months of age, long before babies speak, they will take turns with their parents in back-and- forth vocalizations, facial expressions, and gestures. It has been shown that infants will match the pause duration of their mothers, thereby enabling a rhythm of turn-taking; infants will vocalize, pause, attend to their parents, and wait for their parents’ response.
It seems conversation is not a natural consequence of the ability to learn language; rather, the ability to learn language is, at least in part, a consequence of a simpler genetically hard-coded instinct to engage in conversation. It seems to be this hardwired curriculum of gestural and vocal turn-taking on which language is built. This type of turn-taking evolved first in early humans; chimpanzee infants show no such behaviour.
By nine months of age, still before speech, human infants begin to demonstrate a second novel behaviour: joint attention to objects. When a mother looks at or points to an object, a human infant will focus on that same object and use various nonverbal mechanisms to confirm that she saw what her mother saw. These nonverbal confirmations can be as simple as the baby looking back and forth between the object and her mother while smiling, grasping it and offering it to her mother, or just pointing to it and looking back at her mother.
Scientists have gone to great lengths to confirm that this behaviour is not an attempt to obtain the object or get a positive emotional response from their parents, but instead is a genuine attempt to share attention with others. For example, an infant who points to an object will continue pointing to it until her parent alternates their gaze between the same object and the infant. If the parent simply looks at the infant and speaks enthusiastically or looks at the object but doesn’t look back at the infant (confirming she saw what the infant saw), the infant will be unsatisfied and point again. The fact that infants frequently are satisfied by this confirmation without being given the object of their attention strongly suggests their intent was not to obtain the object but to engage in joint attention with their mothers.
Like proto-conversations, this pre-language behaviour of joint attention seems to be unique to human infants; nonhuman primates do not engage in joint attention. Chimpanzees show no interest in ensuring someone else attends to the same object they do. They will, of course, follow the gaze of others around them—looking in the direction they see others look. But there is a crucial distinction between joint attention and gaze following.
Lots of animals, even turtles, have been shown to follow the gaze of another of their own species. If a turtle looks in a certain direction, nearby turtles will often do the same. But this can be explained merely by a reflex to look where others look. Joint attention, however, is a more deliberate process of going back and forth to confirm that both minds are attending to the same external object.
What’s the point of children’s quirky pre-wired ability to engage in proto-conversations and joint attention? It is not for imitation learning; nonhuman primates engage in imitation learning just fine without proto-conversations or joint attention. It is not for building social bonds; nonhuman primates and other mammals have plenty of other mechanisms for building social bonds. It seems that joint attention and proto-conversations evolved for a single reason. What is one of the first things that parents do once they have achieved a state of joint attention with their child? They assign labels to things.
The more joint attention expressed by an infant at the age of one year, the larger the child’s vocabulary is twelve months later. Once human infants begin to learn words, they start naturally combining these words to form grammatical sentences. With the foundation of declarative labels in place through the hardwired systems of proto-conversations and joint attention, grammar allows them to combine these words into sentences, which can then be constructed to create entire stories and ideas.
Humans may have also evolved a unique hardwired instinct to ask questions to inquire about the inner simulations of others. Even Kanzi and the other apes that acquired impressively sophisticated language abilities never asked even the simplest questions about others. They would request food and play but would not inquire about another’s inner mental world. Even before human children can construct grammatical sentences, they will ask others questions: “Want this?” “Hungry?” All languages use the same rising intonation when asking yes/no questions. When you hear someone speak in a language you do not understand, you can still identify when you are being asked a question. This instinct to understand how to designate a question may also be a key part of our language curriculum.
So we don’t realize it, but when we happily go back and forth making incoherent babbles with babies (proto-conversations), when we pass objects back and forth and smile (joint attention), and when we pose and answer even nonsensical questions from infants, we are unknowingly executing an evolutionarily hard-coded learning program designed to give human infants the gift of language. This is why humans deprived of contact with others will develop emotional expressions, but they’ll never develop language. The language curriculum requires both a teacher and a student.
And as this instinctual learning curriculum is executed, young human brains repurpose older mentalizing areas of the neocortex for the new purpose of language. It isn’t Broca’s or Wernicke’s areas that are new, it is the underlying learning program that repurposes them for language that is new. As proof that there is nothing special about Broca’s or Wernicke’s areas: Children with the entire left hemisphere removed can still learn language just fine and will repurpose other areas of the neocortex on the right side of the brain to execute language.
In fact, about 10 percent of people, for whatever reason, tend to use the right side of the brain, not the left, for language. Newer studies are even calling into question the idea that Broca’s and Wernicke’s areas are actually the loci of language; language areas may be located all over the neocortex and even in the basal ganglia.
Here is the point: There is no language organ in the human brain, just as there is no flight organ in the bird brain. Asking where language lives in the brain may be as silly as asking where playing baseball or playing guitar lives in the brain. Such complex skills are not localized to a specific area; they emerge from a complex interplay of many areas. What makes these skills possible is not a single region that executes them but a curriculum that forces a complex network of regions to work together to learn them.
So this is why your brain and a chimp brain are practically identical and yet only humans have language. What is unique in the human brain is not in the neocortex; what is unique is hidden and subtle, tucked deep in older structures like the amygdala and brain stem. It is an adjustment to hardwired instincts that makes us take turns, makes children and parents stare back and forth, and that makes us ask questions.
This is also why apes can learn the basics of language. The ape neocortex is eminently capable of it. Apes struggle to become sophisticated at it merely because they don’t have the required instincts to learn it. It is hard to get chimps to engage in joint attention; it is hard to get them to take turns; and they have no instinct to share their thoughts or ask questions. And without these instincts, language is largely out of reach, just as a bird without the instinct to jump would never learn to fly.
If you enjoyed this extract, please share it, and of course buy A Brief History Of Intelligence.
For further nourishment of your exquisitely evolved brain, sign up for a paid subscription to The Ruffian, an essential part of your twenty-first century curriculum. I’ll be back with more thoughts of my own next week.
Fascinating and well-written! Addresses so many questions I have about language in such a short space. Interesting how it agrees more with Cormac McCarthy in "The Kekulé Problem" than it does with Chomsky's theory of language - beyond the idea 'Human vs. ape communication is apples and oranges', it doesn't go along with much of the latter's thesis at all.
I'm not sure whether it was right at the time, but it's certainly not right now to say that reinforcement learning is always or even mainly achieved via self-play. The reinforcement learning that forms the second main phase of training an LLM chatbot ("post-training"), turning it from a pure next-token predictor into a turn-taking, "helpful, honest, harmless assistant" persona is done by human feedback, with no self-play at all, and I'm pretty sure the chain-of-thought reinforcement learning in the newer reasoning models is similar. I'd be surprised if this is entirely a very new development, and that reinforcement learning was all done by self-play before this. Either way, it definitely isn't now.
This isn't a central point at all and I thoroughly enjoyed this excerpt, but I thought this was a confusion worth noting.